The 2m peak
Source: my friend Anna

TLDR: the 2m peak is half functional music for sleep/relaxation/meditation (think ‘Rainy Nights for Sleep’) or background setting and half traditional music, with a massive surge in releases in 2024. This suggests mainly algorithmically-generated music, including AI.
Here is the distribution of durations over 256M songs:

We see three distinct peaks at 2m, 3m5s and 4m. Here we focus on the 2m peak. Can we explain it?
First, to get a sense of how abnormal it is, let’s zoom in on track counts for durations between 1m50 and 2m30 at a resolution of one second:
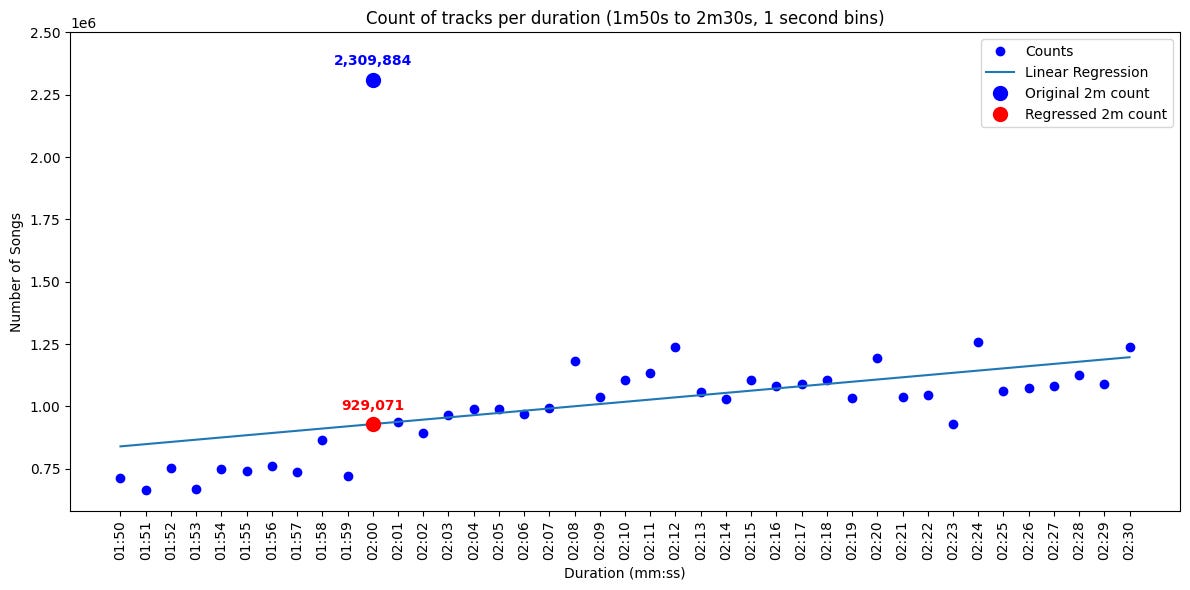
Using a linear regression, we see that the 2m peak contains an abnormal excess of about 1.3M songs! Where do they come from?
The most telling hint is to look at the number of releases per year:
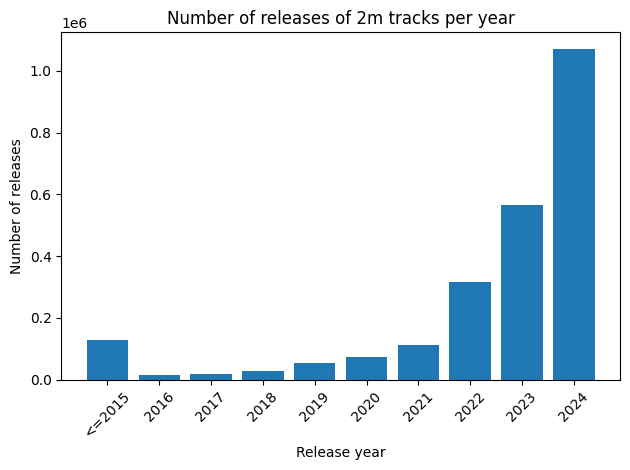
This strongly smells like computer-generated, not to say AI-generated music! Interestingly, the 2m mark was the maximum generation length of the AI platform Suno’s V3 (Spring 2024).1
And, in fact, 2m tracks hold the record, with 32% of them having been released in 2024:
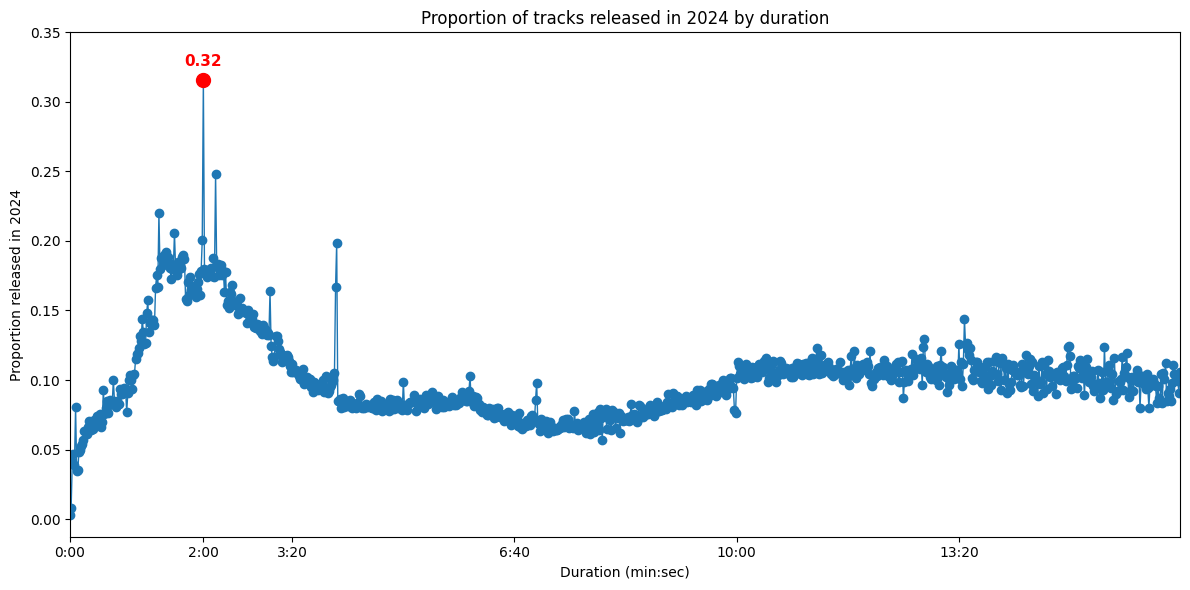
Let’s zoom into musical features to see what type of 2m tracks are released and try to identify whether AI is really the culprit here (spoiler: yes and no):
Musical Features
Instrumentalness, danceability and valence
We inspect the three following features:
Instrumentalness: a number between 0 and 1 which predicts whether a track contains no vocals (an instrumentalness of 1 means no vocals).
Danceability: a number between 0 and 1 which predicts whether a track is suited for dancing (very suited for dancing is 1).
Valence: a number between 0 and 1 which predicts the positiveness of a track (very positive/happy is 1).
Let’s look at instrumentalness, averaged among all tracks of the same duration:
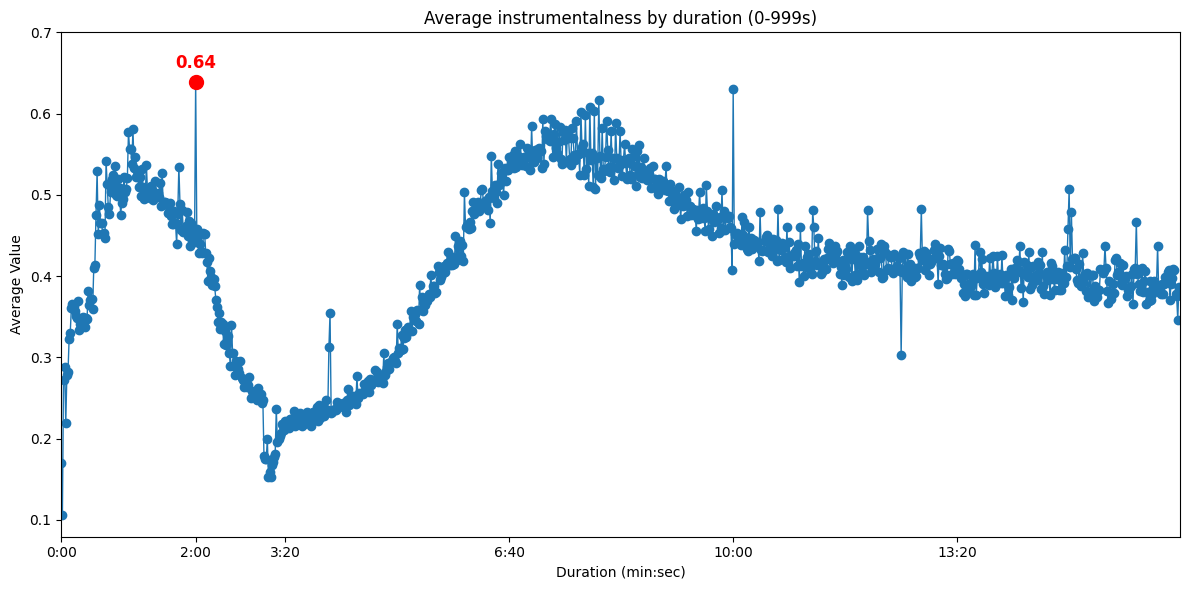
We see a sharp rise at the 2m mark. For valence and danceability we see a sharp decrease:
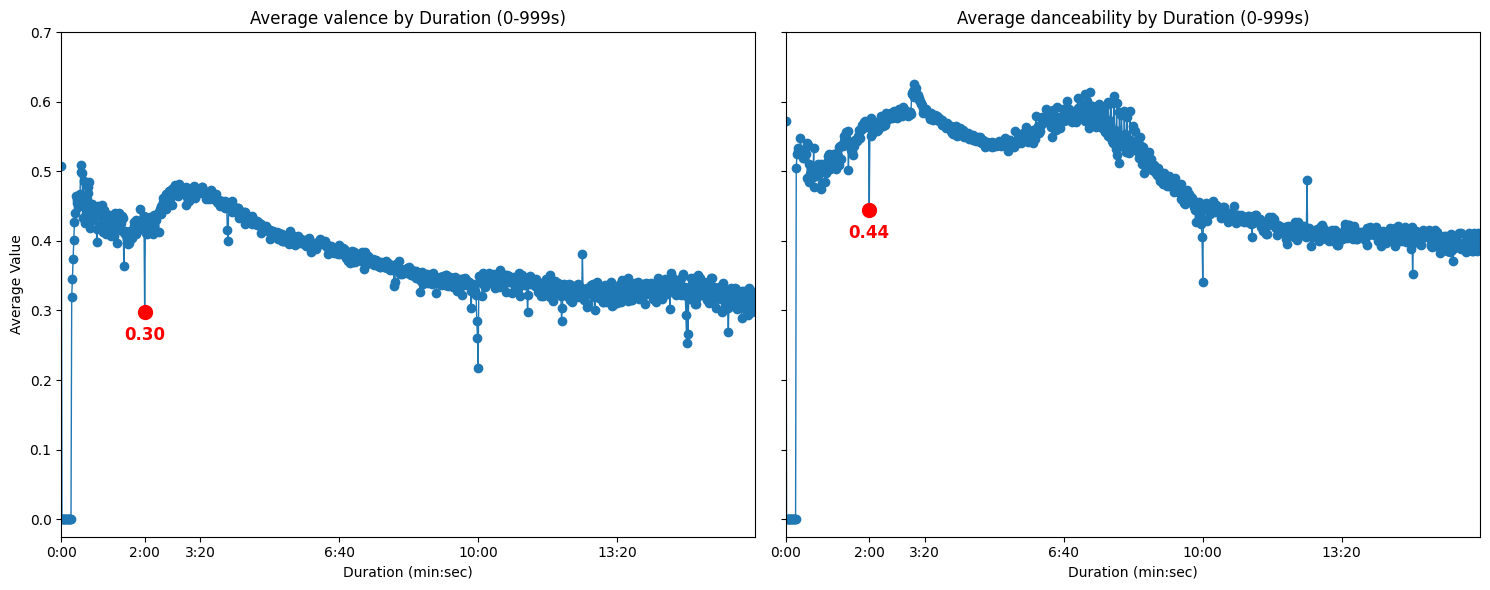
This strongly suggests that a differentiating factor of the 2m peak from neighbouring durations is an increased presence of high-instrumentalness, low-valence, low-danceability tracks which typically correspond to functional music (sleep/relaxation) or background/lo-fi.
Let’s look at the distributions of instrumentalness/valence and danceability in the 2m peak:
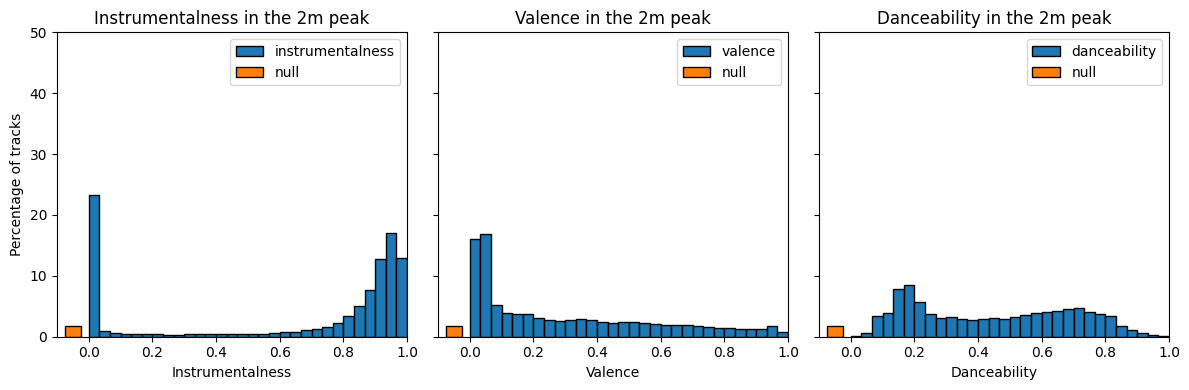
We notice in each case a ~2% proportion of tracks where the feature is null, which we interpret as a failure of the feature-computing algorithm on those tracks, i.e. ill-defined features for the tracks.
To get a sense of how singular these distributions are, let’s look at them one second later, at 2m1s:
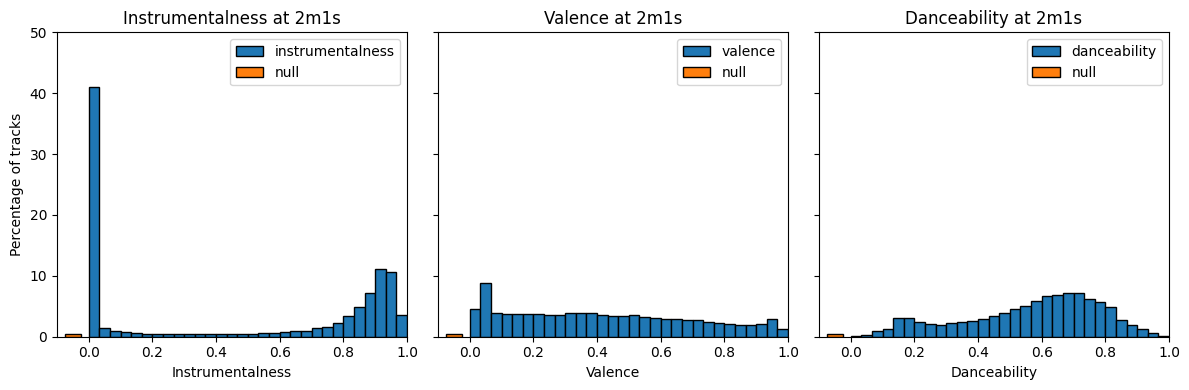
Hence, it is clear that the 2m peak contains an abnormally high amount of super-chill tracks, which we define to be tracks with > 0.5 instrumentalness (or null), < 0.5 valence (or null), and < 0.5 danceability (or null).
The 2m peak contains 1,045,565 super-chill tracks.
Here is the proportion of super-chill tracks per duration:
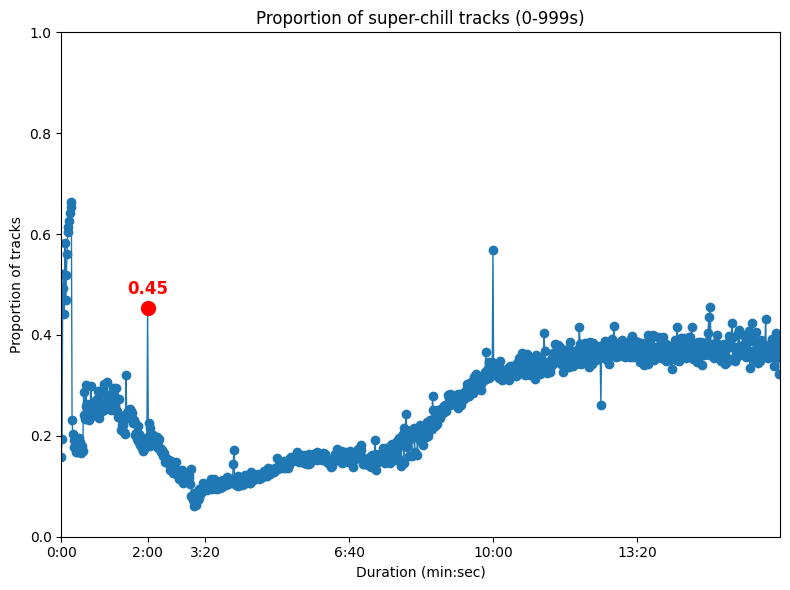
Hence, we found a good suspect: the 2m peak contains an abnormal proportion of 45% of super-chill tracks!
Super-chill tracks
Let’s look at 10 randomly sampled track names in that set: ‘Raining into the Ocean Waves’, ‘Throat Chakra - 396 Hz’, ‘Blue Dreams, Pt. 15’, ‘Rain Sounds Pt. 15’, ‘Arise’, ‘Dreamy’, ‘Baby Lullaby’, ‘Seraphic Soul Spa’, ‘Fear Removal Tones’, ‘Haunted Smokey Mountain’. It is surprising to us that most of these tunes have valence close to 0, e.g. ‘All Night Pure Calm’, ‘Fine Rain Sound’, ‘Soft Mist Melodies’ have valence equal to 0, whereas they intuitively evoke neutral to mild positiveness.
These track names evoke functional music used for sleep, relaxation, and mood-setting, but several genres could be represented: from unclassified sounds for sleep to lullabies, lo-fi, or space music.
We can dig deeper with semantic clustering2 of these tracks’ names:
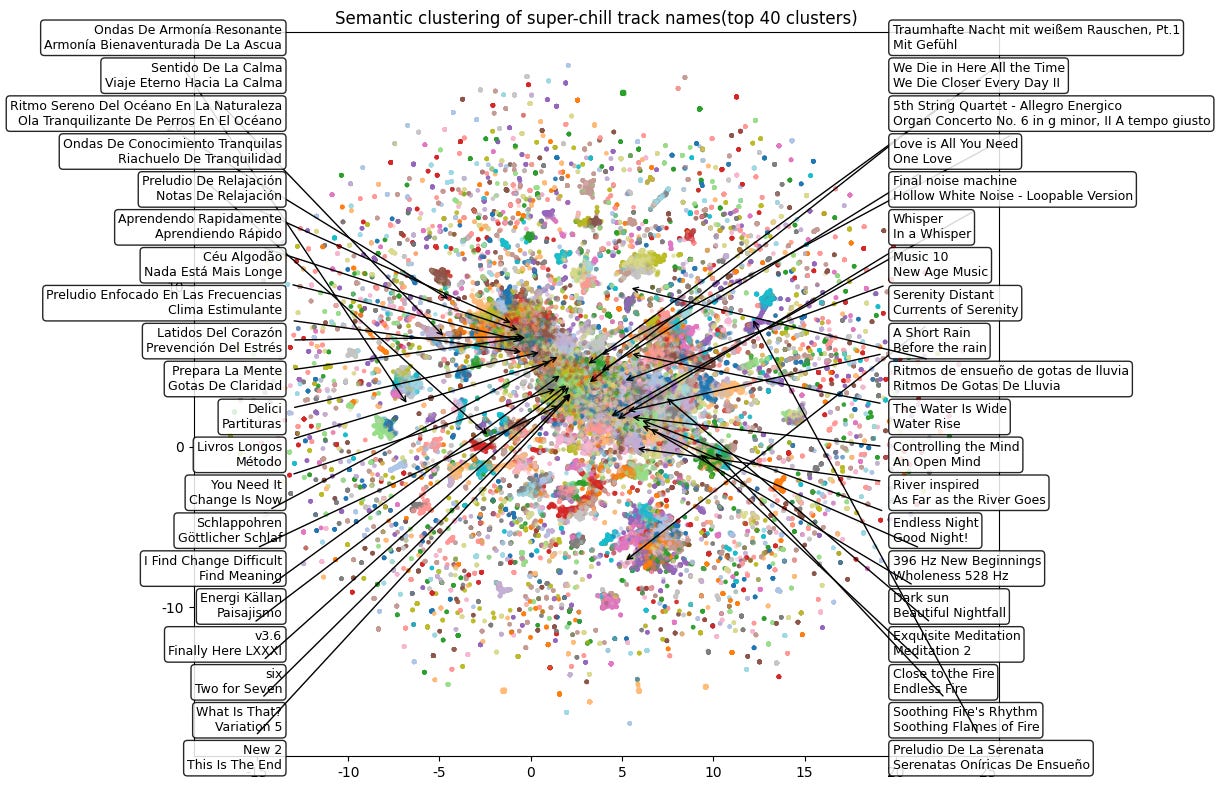
This is a lot, but we see: Spanish relaxation corner: center top left; water-themed (rain, river): center top right; frequency-based (e.g. 396Hz): center bottom right; meditation-based: center bottom right; fire-themed: center bottom right; white noise: center; classical music: center top3 .
Schematically, this gives:
Top left of the space: Spanish-titled functional music
Right part of the space: English-titled functional music (sleep/relaxation)
Center: noise
Bottom left: harder to interpret; listening to a handful of songs indicates cinematic, ambient, lo-fi music
Not super-chill tracks
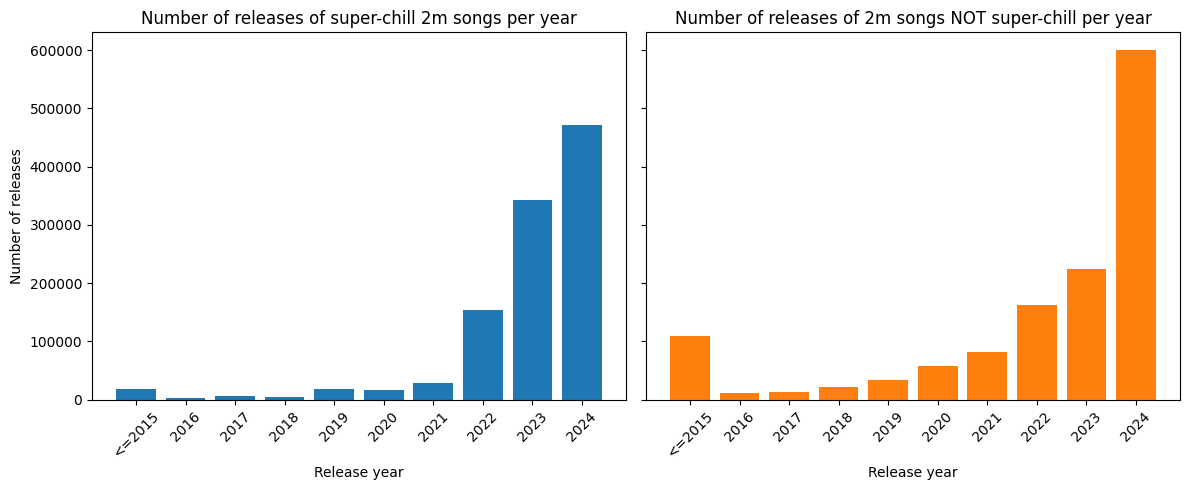
As we can see, contrarily to super-chill tracks, non-super-chill tracks have seen a sudden surge in 2024, which strongly suggests that something changed in 2024, allowing for the mass production of songs — assuming that non-super-chill tracks are more like typical songs.
Interestingly, for approximately the same amount of music produced, the super-chill tracks are produced by 6x fewer artists.
These plots suggest that half of the 2m peak is due to super-chill tracks (which do not necessarily need AI to be generated) and half of it due to AI-generated songs.
Conclusion: AI or not AI?
The 2m peak is a significant anomaly due to the recent surge, between 2022 and 2024 of music that is easy to mass-produce. We believe that two relatively independent factors are at play and that they share 50% of the responsibility in 2024:
Super-chill tracks. This category, of high-instrumentness, low-danceability and low-valence music, contains almost only functional music for sleep/relaxation/focus/background. Arguably, one does not need AI to generate the track ‘Harmonic Focus (30 Hz Binaural Frequency)’ or ‘Loopable Rainfall’ and they can be mass-produced using algorithms. However, AI music generation tools are most likely used too (especially for ambiance-setting tracks?). This genre is appealing for algorithmic generation, as it is not too complex but is consumed a lot; see this post.
Not super-chill tracks. This category most likely sounds a lot more like music and has seen a dramatic increase in the number of tracks in 2024. Here we hypothesise that AI music generation tools are the culprit, noting that the 2-minute mark is consistent with limits of models like Suno at the time.4 Further study of this category is needed.
Hence, our conclusion is that the ~1.3M tracks in excess in the 2m peak are 100% programmatically generated but maybe only 50-75% AI, at least for now.
Word embeddings (all-MiniLM-L6-v2), PCA 50, MiniBatchKMeans (k=200), UMAP (15 neighbours, min dist 0.05, euclidean).